
Hope all my readers are doing good. Before you Jump on to this blog, make sure you have read the following post: “An Unsung Art” (https://www.dataseers.ai/an-unsung-art/)
I am excited because we are going to experience the power of inbuilt function in ECL language. The best part of this exercise is that you will not just learn how to use the function as is, but also to use it in combination to make it even more effective.
We concluded in my earlier blog with a fun challenge for you all to get me the count of all records. Well… did you get it? If not, don’t worry, I got you covered. We will move on…
Let’s dive right in…
In ECL we have several inbuilt functions to make our lives easier. Now that we have already read the guidelines (download the file by clicking this link: [download id=”4687″]), let’s see how many records or rows of data we would be dealing with.
For SQL user basically you are trying to do this:
SELECT COUNT (DISTINCT UniqueIdentifier) FROM taxids;
In ECL, we do the below highlighted line:
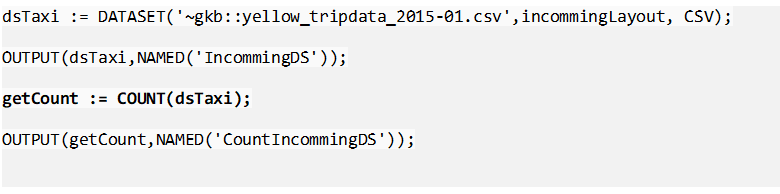
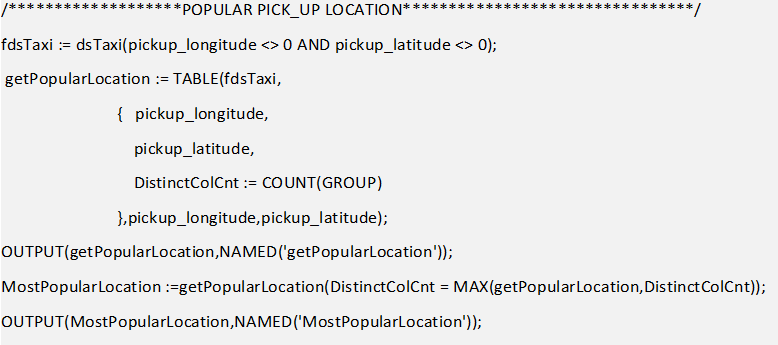
COUNT is the keyword used to get the record count, now let’s try using count function with TABLE to get Unique values and their count grouped by one or more fields. In the below example I am using “pickup_longitude” and “pickup_latitude” fields. The COUNT(GROUP) get the count of unique value from both the fields and to just get some useful insight. Let’s get the most popular pickup location by using yet another inbuilt function: MAX().

NOTE: If you are using Visual code to run the code, press F5 for syntax check and F7 for compile and execute. The below link can help you setup visual code in case you are having issues.
Let’s get our hands dirtier by dealing with a clean dataset. Always remember your data need to be clean and precise for better analytics. What if something went wrong with the recording system (i.e. the system that collects all these data in real time) and we end up with duplicate entries! The result: it will heavily affect out decision making. So, it is important to clean and understand the data.
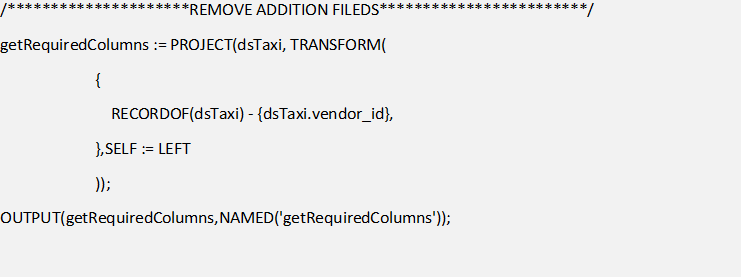
The first step of cleaning that I would suggest, is to create a slim dataset where in you just keep the fields that you require and remove the others. In the example below, we are using mostly all fields that can be used but to show how this can be achieved, I am removing vendor_id field from the taxi dataset.
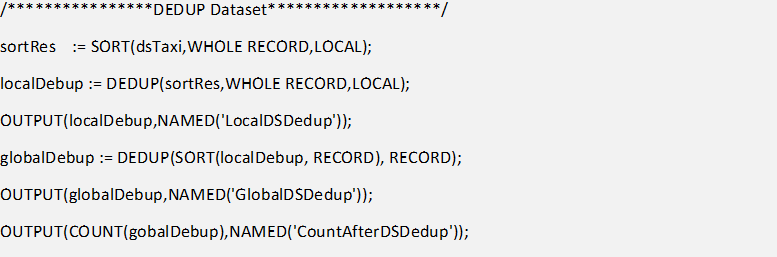
So now we have created a slim dataset, next step is to remove all the duplicate records. For this I will be making use of various Inbuilt functions together such as SORT, LOCAL and DEDUP. Just to get a better performance and speed I would first parallel DEDUP on each node and then go for a global DEDUP. Always remember, when you are doing any local operation, the dataset should be distributed systematically across the nodes.
Moving forward now, we have a clean dataset – so let’s start doing some basic analytics. For instance, I see a field called payment type, and I would like to know what are the various type of payment methods we can possible have – Basically, I want to know all the Unique values that column can have, for that I will be using TABLE.

Now as I know all the unique values of payment methods, I can create a Dictionary for lookup.

Well, what do you think guys!
That’s a lot to learn in a session I believe, but don’t you worry!
Take it slow and churn all the bits so that you get the hang of using of all the functions right.
In our next blog we will use yet another built-in module called “ML_Core” and yes you are right – Machine Learning!
Also, I will try keeping my post tiny and precise after this. Just wanted to get all the basics out clear.
See you soon! Until then, Adios!