
Programming is a distinctive art carving around logic and building on debris of unsuccessful trials. It takes a lot of effort, persistence and will of the mind, body and soul to emerge as a successful coder. This is what my voyage so far has been teaching me.
Let’s talk HPCC – the ground, ECL – the horse and being a smart coder – the jockey!
Allow me to take you all through an exciting, uphill but rewarding journey of strengthening myself into a self-paced and successful learner and performer. Delivery is the key!
I started coding in ECL from the time I became a part of Dataseers Inc. and mark this – it was the first time I got to work on Big Data.
I must say – my SQL development experience during my early career has enabled me quite well into applying logic and coding best practices into big data programming.
At this point, the greatest thing that I feel I can give back is to share what I learned with you – my community. So why wait! Let’s go through a series of blog posts wherein I will be transitioning and enabling you to work with diverse data sets and get going with some good hands on big data coding using ECL.
Brush up your Basics of ECL
Okay, this is the first step. Go to the below links and quickly brush up some basic definitions, concepts and all that matter needed for your head-start in ECL programming.
http://cdn.hpccsystems.com/releases/CE-Candidate-6.2.12/docs/HPCCDataHandling-6.2.12-1.pdf
You’ll be lost if you don’t do this ?
Know your Data
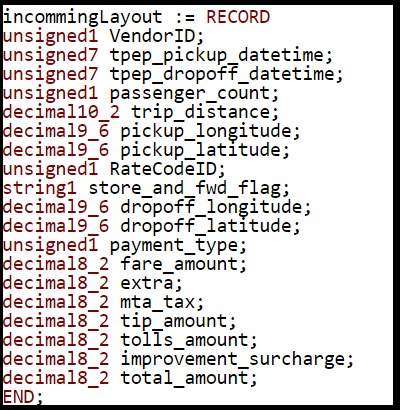
And yes, before you jump into getting your hands dirty with coding, it is extremely important that you understand your data. The dataset that we will be working on for a while now is collected from the NY City Taxi drivers. You can also refer to this as a “record layout” for future reference.
This dataset is uploaded and available in csv format – in the landing zone: link below. (don’t know what it means? Go upward – get into the link – and read! That’s why I say – read!)
http://play.hpccsystems.com:8010/#/stub/Files-DL/LandingZones-DL/LandingZones
The csv file name you should be looking for is – yellow_tripdata_2015-01.csv – scroll through and look for it!
Once you find it, click the checkbox alongside to select it –

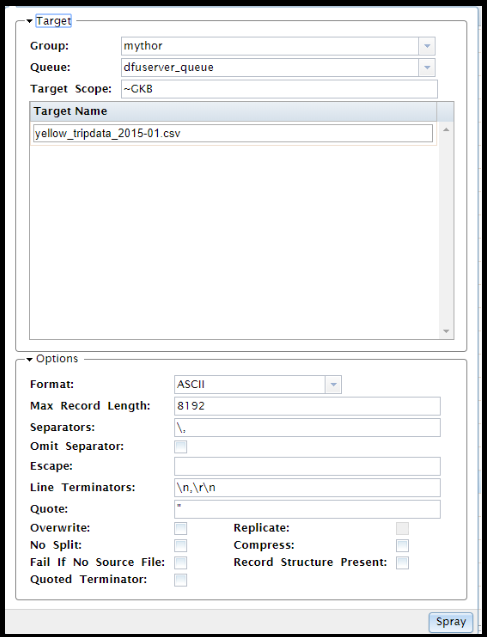
Then click on the ‘delimited’ tab, the below window pops up: Let the defaults remain, while you can define your target scope. I usually key in my initials, so I know where to go later on – a folder structure will be created with my initials ~GKB – mind the syntax! Your target name is the csv filename already selected.
That’s it! – Click SPRAY.
You will see the Spray work unit generated like the one below. You can go through all the additional details about target, source etc.
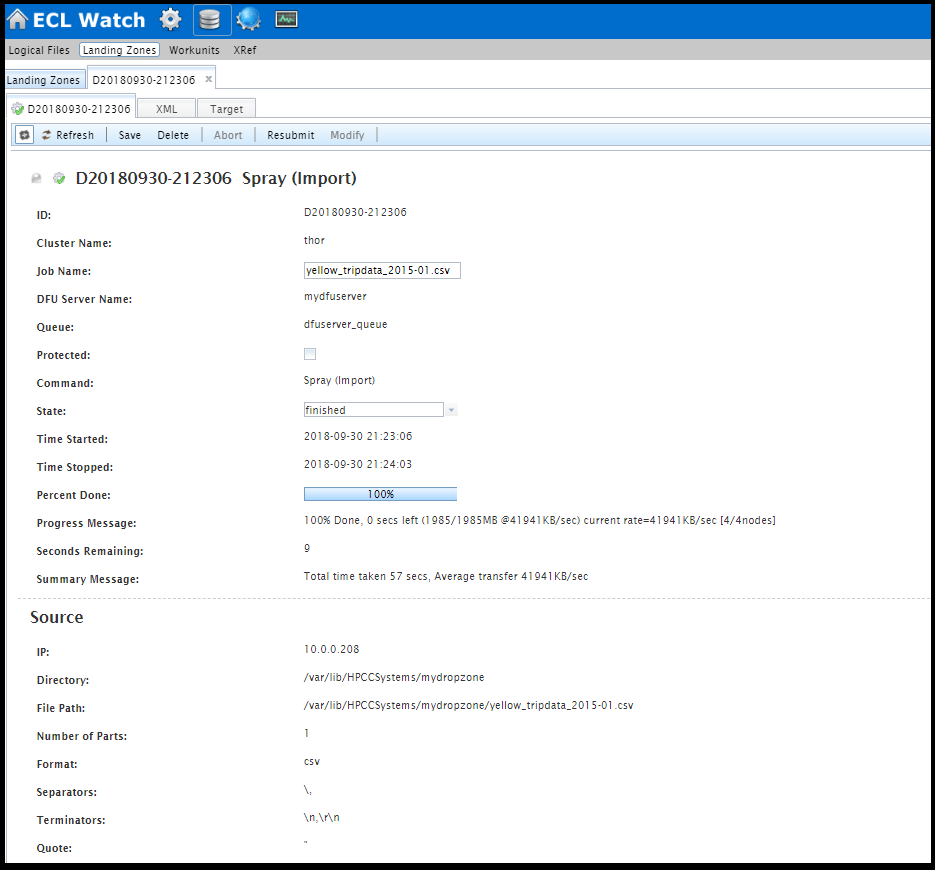
The file gets moved into the cluster – and that’s how you create a logical file, which looks like the following:
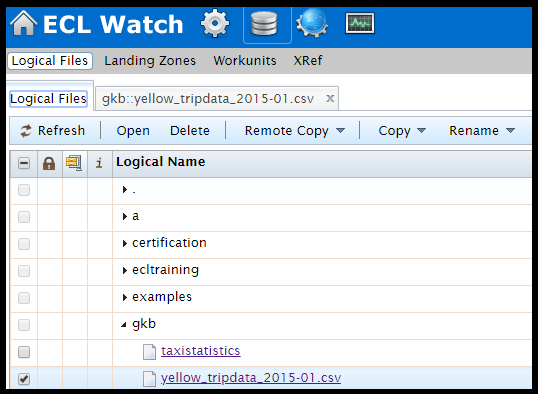
Yeah if you can see you initials in the logical files along with the csv file you have successfully sprayed the file.
Let’s know more about the data. Click on the file name and then contents tab to look for yourself what you have sprayed. But if you notice it’s not human readable as it is in one single line column and all comma separated. So, what we do next …
Read the Data
Now let’s read the dataset by providing the ‘record layout’ mentioned above.
Code:
How to execute this code can be done by following the below link:
https://github.com/hpcc-systems/Solutions-ECL-Training/blob/master/Taxi_Tutorial/README.md
Moral of the Story
You made up your mind to learn and excel in ECL coding. We saw how to SPRAY a file and READ the data. That’s a great progress!
Here is the link where you can start playing around:
Keep playing around with all the options and tabs that you find in ECL Watch – be good explorers! Got any Questions? Post them here, I’ll get back to you.
Feel like exploring even more? Ok, try to get me the count of the records in the data file. No worries if you flunk ? I’ll explain in my next post, along with some more key functionalities and features that you need.
Until then, stay tuned! Happy Coding! Let’s become smart coders – the rare artists!